The types of production system are depicted in the following image.
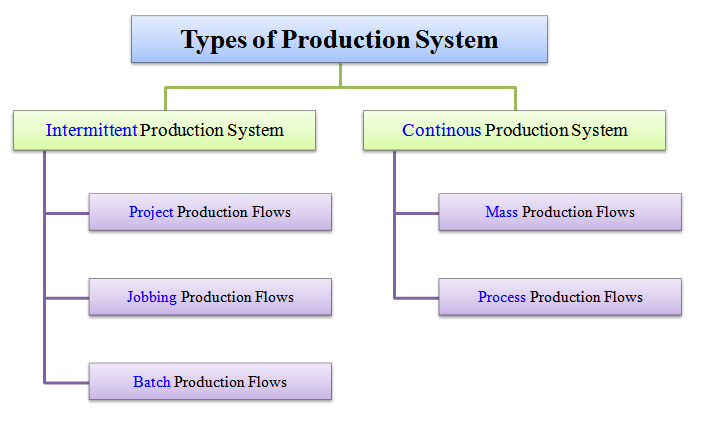
Image credits © Moon Rodriguez.
The types of production system are grouped under two categories viz.,
- Intermittent production system, and
- Continuous production system.
Now let's discuss in detail each of the above-mentioned categories.
 Intermittent production system
Intermittent production system
Intermittent means something that starts (initiates) and stops (halts) at irregular (unfixed) intervals (time gaps).
In the intermittent production system, goods are produced based on customer's orders. These goods are produced on a small scale. The flow ofproduction is intermittent (irregular). In other words, the flow of production is not continuous. In this system, large varieties of products are produced. These products are of different sizes. The design of these products goes on changing. It keeps changing according to the design and size of the product. Therefore, this system is very flexible.
Following chart highlights the concept of an intermittent production system.
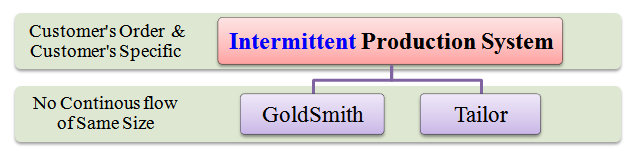
Following are examples on the intermittent production system. Please refer above chart while reading examples given below.
- The work of a goldsmith is purely based on the frequency of his customer's orders. The goldsmith makes goods (ornaments) on a small-scale basis as per his customer's requirements. Here, ornaments are not done on a continuous basis.
- Similarly, the work of a tailor is also based on the number of orders he gets from his customers. The clothes are stitched for every customer independently by the tailor as per one's measurement and size. Goods (stitched clothes) are made on a limited scale and is proportional to the number of orders received from customers. Here, stitching is not done on a continuous basis.
The features of an intermittent production system are depicted below.

The characteristics of an intermittent production system are listed as follows:
- The flow of production is not continuous. It is intermittent.
- Wide varieties of products are produced.
- The volume of production is small.
- General purpose machines are used. These machines can be used to produce different types of products.
- The sequence of operation goes on changing as per the design of the product.
- The quantity, size, shape, design, etc. of the product depends on the customer's orders.
The types of intermittent production system include:
- Project production flows,
- Jobbing production flows, and
- Batch production flows.
Continuous production system
Continuous means something that operates constantly without any irregularities or frequent halts.
In the continuous production system, goods are produced constantly as per demand forecast. Goods are produced on a large scale for stocking and selling. They are not produced on customer's orders. Here, the inputs and outputs are standardized along with the production process and sequence.
Following chart highlights the concept of a continuous production system.
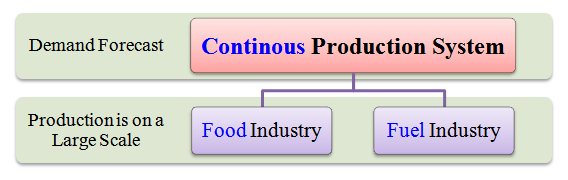
Following are examples on the continuous production system. Please refer above chart while reading examples given below.
- The production system of a food industry is purely based on the demand forecast. Here, a large-scale production of food takes place. It is also a continuous production.
- Similarly, the production and processing system of a fuel industry is also purely based on, demand forecast. Crude oil and other raw sources are processed continuously on a large scale to yield usable form of fuel and compensate global energy demand.
The features of a continuous production system are depicted below.

The characteristics of a continuous production system are listed as follows:
- The flow of production is continuous. It is not intermittent.
- The products are standardized.
- The products are produced on predetermined quality standards.
- The products are produced in anticipation of demand.
- Standardized routing sheets and schedules are prepared.
The types of continuous production system include:
- Mass production flows, and
- Process production flows.

